Introductory Tutorial on Checkable Proofs
The fact that conventional mathematical language is not strictly formal and that therefore any process of formalization requires some changes, raises the prospect of a wholesale transformation of mathematical language that effectively incorporates mathematics into one or another computer programming language. ProofCheck is based on the idea that no wholesale transformation is necessary and that those changes which are necessary should be done minimally intrusively.
In particular it is the aim of proofcheck to intrude on an author's preferences as little as possible while at the same time providing access to default rules of inference and common notions files.
A. Language of the Common Notions File
ProofCheck has a set of expressions and a concomittant syntax that is "built-in" in the sense that the easiest way to use the default rules of inference and common notions files is to use it. It is developed in the file common.tex. This section outlines the syntax of this built-in language.
We begin with a quick introduction to the language used in these files.
The parser assumes that all mathematical expressions are built up by substitution from basic forms which are expressions consisting of constants and variables. Variables are replaced in the substitution process by other variables or other basic forms.
For example, suppose that the set of basic forms consisted of
'(x + y)', '(x - y)', and '\sqrt A',
where the variables occurring here are 'x', 'y', and 'A'. The valid mathematical expressions generated by this set of basic forms would include expressions such as
'\sqrt(C - D)', '(x + \sqrt(y - (A + b)))', '\sqrt \sqrt x', etc.
The following two basic forms are built into proofcheck for defining terms and formulas:
'(x \ident y)'
'(\pvar \Iff \qvar)'
Definitions constructed using these two forms create new basic forms. For the most part it is the case that a basic form is just the left side of some definition. A basic form can however be created by merely specifying a primitive or undefined form. Some are also generated automatically by parenthesis removing conventions for infix operators.
Included with ProofCheck is a set of basic forms which is "built-in" in the sense that the default rules of inference and common notions files are based on them. An author can use as much or as little of this development as he or she likes. It is developed in the file common.tex. This section outlines the syntax of this built-in language.
We begin with a quick look at the sentential logic.
1. Sentential Logic Operators
Most of the sentential operators used are shown in the table below.
The symbol used in these source code files appears in the first column of the table below. The TeX or Morse font character used for these symbols is given the third column.
| Source Code | Meaning | Printed Character |
| \And | Logical Conjunction | 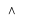 |
| \Or | Logical Disjunction | 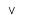 |
| \c | Logical Implication | 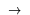 |
| \Iff | Logical Equivalence | 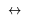 |
| \Not | Logical Negation | 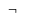 |
An author who chooses to use a different source code symbol or a different printed character used can do so without altering the default files. An author who wished to use \AND, for example, in source code files as the symbol for logical conjunction could define:
%def_symbol: \AND \And
Similarly an author who wished to use '\&' as the printed character for conjunction could use a TeX macro to define:
\def \And {\mathrel{\&}}
One of the guiding ideas of ProofCheck is that the language used by an author should be a free choice to the extent that this is feasible.
Because the '\And' symbol used by the default rules of inference and common notions files is an infix operator, the use of some a symbol with a different syntax, say a prefix operator, would require an author to convert or revise those files.
In using infix operators, outer parentheses are required. The only sentential operator which is not given an infix syntax is negation. For pure sentential logic expressions sentential variables, e.g. \pvar, \qvar, \rvar, etc. must be used. The reader is invited to try expressions such as (\pvar\And \qvar) and \Not(\pvar\c \qvar \Or \rvar) using the Online Expression Parser. For default precedence values see the precedence table
2. Equality and Quantifiers
The default rules of inference and common notions files are based on a predicate logic which differs slightly from the conventional.
It can be described as the result of adding a null object, similar to Python's None or Microsoft's Null, and the Hilbert epsilon symbol to a conventional predicate logic with equality.
3. Descriptions
Definite and indefinite descriptions are included in the default rules of inference and common notions files. The definite description is:
\The x \pbar xThe indefinite description is:
\an x \pbar x
a. Definite Descriptions
Assignment statements are often useful when it is known that exactly one object satisfies a predicate '\pbar x'. The quantifier which makes this assertion is:
\One x \pbar xThe assignment statement is:
(a \ident \The x \pbar x)See the note 8 in the proof in the Geometry Example.
b. Indefinite Descriptions
Assignment statements can also be used with indefinite descriptions. If one knows for example that:
\Some x \pbar xOne may usefully assign:
(a \ident \an x \pbar x)from which it follows that:
\pbar a
c. Cases and Conditionals
The form:
(\pvar \cond x)denotes x only if \pvar is true and does not exist.
The form
(\pvar \cond x \els y)denotes x if \pvar is true and y otherwise.
4. Basic Set Theory Operators and Relation Symbols
TeX has built-in symbols for the most basic set theory operators and relations. The default common notions file uses most but not all of these. As with the sentential logic symbols substitutions can be made to suit an author's preference.
| Source Code | Meaning | Domain |
| \cap | Intersection | Standard TeX |
| \cup | Union | Standard TeX |
| \in | Elementhood | Standard TeX |
| \i | Subset Relation | Plain TeX |
| \Cmpl | Set Complement | Common TeX |
| \setdif | Set Difference | Common TeX |
| \symdif | Symmetric Difference | Common TeX |
For example (x \in A \And A \i B \c x \in \ B ) is a formula that parses. (It is also Theorem 11.7 in common.tex and can therefore be referenced with the number 011.7.)
For default precedence values see the precedence table.
To get beyond the built-in language an author can introduce new basic forms either by using definitions or by simply declaring them with a ProofCheck macro.
B. Statement of Definitions
To get beyond the in language of the common notions file an author can introduce new basic forms either by using definitions or by simply declaring them with a ProofCheck macro.
1. Structure of Definitions
Because definitions are used as propositions internal to the inferential system along with axioms and theorems, the substitutions which generate the complex terms and formulas from the basic terms and formulas must necessarily be those which are inferentially valid. Although it is possible to describe any language which ProofCheck can parse using a context-free grammar, it should be noted that the production rules of such a grammar can be obtained in a simple manner from the set of basic forms. These production rules for the non-schematic subset involve only four non-terminal symbols.
ProofCheck's grammar does not accomodate contextual definition. For example one cannot define addition of classes [x] by defining ([x] + [y]). Here the expression ([x] + [y]) is a composite involving distinct basic forms (A + B) and [x]. These need to be defined separately. Similarly the commonly used definition of limit as ((limit x f(x) = L) if and only if For every epsilon, etc.) is contextual and not admissable. The left side contains previously defined basic forms for equality, (A = B), and functional evaluation, f(x). To define the limit as the number L having such and such a property one can use a definite description.
Definitions of terms must have the form:
(<new-basic-term> \ident <term>)Definitions of formulas must have the form:
(<new-basic-formula> \Iff <formula>)The right side of a definition may be any valid term or formula. The expression on the left must begin with a constant. In most cases, although this is not required, the constant will be either a constant that is unique to that basic form, or a left parenthesis. The variables which occur in this basic form less than once are by definition its free variables. It is required that the free variables of the left side of a definition be the same as the free variables on the right side of that definition.
Most definitions therefore introduce some new constant and usually this constant needs to be set up with a TeX macro. In the divisibility example a new constant "divides" is introduced in Definition 1.1. Without a macro, TeX would fracture this constant into italic variables yielding an expression equivalent to ddiives! The macro needs to be something like:
\def\divides{\mathrel{\rm divides}}This macro may entered either into the document itself or into an include file such as divides.tdf. Most documents should have an associated include file for the macros which set up all the new constants introduced in the definitions of the document file.
b. New Term Constants
In common.tex the empty set is defined as the set of all x such that the false statement is true:
(\e \ident \setof x \false)The new constant on the left is taken care of with the TeX macro
\def\e{\emptyset}which is in the file common.tdf (as well as in common.ldf).
c. New Infix Operators and Precedence Declarations
When an infix operator such as divides is defined as in the following definition:
((a \divides b)\Iff \Some k \in \nats (b = k \cdot a))not only is it necessary that the constant "divides" be set up with a TeX macro it is also necessary to create a precedence value for this operator. This is done with a ProofCheck macro:
%set_precedence: \divides 6in general:
%set_precedence: <infix-operator> <value>As in the case of the TeX macro establshing "divides" as a constant, this macro may be stored either in the document file itself (before its use in the definition), or (better) in a ".tdf" or ".ldf" file. Choice of a suitable precendence value can be made based on reference to the existing precedence values.
c. New Prefix Operators
Similarly, the definition of the maximum of a set, introduces a very simple basic form with a prefix constant:
(\Max A \ident \The x \in A \Each y \in A (y \le x))Just as in the previous cases a TeX macro is needed to establish Max as a constant:
\def\Max{\mathop{\rm Max}}An author who chooses to use a different source code symbol or printed character used can do so without altering the default files. An author who wished to use '\AND', for example, in source code files as the symbol for logical conjunction could define:
%def_symbol: \AND \AndSimilarly an author who wished to use '&' as the printed character for conjunction could use a TeX macro to define:
\def \And{\mathrel{\&}}Because the '\And' symbol used by the default rules of inference and common notions files is an infix operator, the use of some a symbol with a different syntax, say a prefix operator, would require an author to convert or revise those files.
In using infix operators, outer parentheses are required. The only sentential operator which is not given an infix syntax is negation. For pure sentential logic expressions sentential variables, e.g. '\pvar', '\qvar', '\rvar', etc. must be used. The reader is invited to try expressions such as
(\pvar \And \qvar)and
\Not(\pvar \c \qvar \Or \rvar)using the Online Expression Parser.
2. Unwrapping Theorems
It is advised that following each definition the author should state at least one theorem which makes readily accessible, inferential consequences of the definition. Two chapters of common.tex are devoted primarily to such definition "unwrapping" theorems. For definitions of terms it is also advised that an existence theorem be stated, which if it does not characterize the existence of the defined object should at least state useful necessary conditions.
3. Undefined Form Declarations
When a basic form is needed and not defined, either because it is truly primitive such as "(x \in y)" or just a form whose definition is inconvenient, it may be delcared using a ProofCheck macro. For example the file geom.tex contains the ProofCheck macro:
%undefined_term: \PointUndefined basic formulas are added using
%undefined_formula: <new-formula>
C. Numbering
ProofCheck assumes a specific numbering system for propositions. The proposition numbering is mirrors either the chapter numbering or the section numbering.
1. Proposition Numbering
Every theorem to be checked or proposition used as a reference must have labelling numeration of the form:
<number> . <number>Any such theorem or proposition must be introduced using a line beginning:
\prop <number>.<number>When using plain TeX The number before the dot is the chapter number. In LaTeX using the with section headers unless this is declared otherwise with as for example:
%major_unit: chapter
2. Chapter or Section Numbering
In TeX chapter numbers must be established using:
\chap{ <number> . <title> }In LaTeX, ProofCheck recognizes existing LaTeX section headers:
\sectionby default. Rather than look for a number it counts these section headers.
Insertions and deletions which disturb consecutive numeration may be fixed by running renum. Because numbering is easily repaired later, initial numbering does not need to be sequential and may be as arbitrary as is convenient.
The macros '\prop' and '\chap' are defined in utility.tdf and may be redefined without affecting either parsing or checking.
3. Note Numbering
A note is a statement in a proof that may be used later in that same proof and may itself require proof.
Notes have the form:
\note <number> <formula> [<justification>]For example to label '$(x \in B)$' as note 3 we would write:
\note 3 $(x \in B)$Insertions and deletions which disturb consecutive numeration may be fixed by running renote.
D. Proof Syntax
Proofs recognized by ProofCheck are either short proofs consisting of a single justification or standard proofs containing a sequence of notes terminated by a QED. Intervening material is not a problem. After each note ProofCheck searches for another note or a QED, passing over anything else it finds except for another proposition marked with a '\prop' which is an error.
1. Short Proofs
A short proof consists of a numbered proposition followed, either on the same line or on the next, by a single justification.
A short proof is checked by searching the rules of inference file for a rule which matches it.
The actual expression which is matched against rules of inference is formed as follows: It begins with the proposition whose proof is sought. It is followed by the symbol '<=', and then followed by the expression obtained from the justification, except for the "\By" symbol, replacing each numerical reference with the expression to which it refers.
Constants such as commas and semi-colons are in effect defined by the way that they are used in the rules of inference.
2. Simple Notes
Many notes of a proof consist simply of assertions that themselves require proof and once proved can be used later in that same proof.
A note must be introduced with the '\note' macro, be followed by an integer, the assertion, to be proven, and optionally by a justification. For example we might have a "note 5" as follows:
\note 5 $(x \in B) \By 1.2;.3,.4This would mean that to notes 3 and 4 were being used together with a theorem 1.2. Suppose that note 3 and 4 were as follows:
\note 3 $(A \i B)$
\note 4 $(x \in A)$
and that theorem 1.2 was as follows
\prop 1.2 $(t \in x \And x \i y \c t \in y)$ .In this case the note will be checked if the following rule is located in the file rules.tex:
$\rvar$ <= $(\pvar \And \qvar \c \rvar)$;$\pvar$,$\qvar$'\rvar' is matched with the goal '(x \in B)'. Theorem 1.2 is matched against '(\pvar \And \qvar \c \rvar)', '\pvar' against '(A \i B)' and 'qvar' against '(x \in A)'. The match succeeds even though '\pvar' and '\qvar' are reversed in Theorem 1.2 assuming that theorems asserting the commutative and associative properties of '\And' are stored in the properties file.
3. Justifications
Justifications are expressions near the right margin which justify one step of a proof, or in the case of a short proof, constitute the proof. Justifications are introduced using the 'By' macro and followed ether by reference expressions and punctuation as in
\By 3.3;2.2,.6or by a single justification letter.
4. Reference Expressions
There are four different kinds of these expressions. A reference expression may refer to:
a. Another Note in the Same Proof
When a reference expression begins with a decimal point then it refers to another note of the proof. So ".3" for example refers to "Note 3".
b. Another Proposition in the Same Document
When a reference expression begins with a numeric character other than "0" it refers to some other proposition in the same document. So "3.3" for example refers to proposition 3.3.
c. A Proposition in the Default External File
When a reference expression begins with the character "0" it refers to a proposition in another file. By default this file is common.tex. Thus "01.2" refers to Theorem 1.2 in the file common.tex.
d. A Proposition in Some Other External File
When a reference expression begins with a lower case letter or letters and is followed by the usual numerals-dot-numerals expression, it refers to some other file. The author may set up and use as many such files as he or she desires. To set up a such a reference a ProofCheck macro is used. For example:
%external_ref: abc filefoo.texenables references such as "abc12.34" to refer to Theorem 12.34 in the file filefoo.tex. Similarly to use this file instead of common.tex for reference expressions beginning with "0" the macro
%external_ref: 0 filefoo.texwould be used.
5. Reference Punctuation
Reference expressions in a justification must be separated from each other, and may even be grouped, with punctuation symbols.
The symbols used as punctuation are:
( ) + , - : ; |The capital letter U also functions in some sense as a punctuator.
A semi-colon is used to separate a major premise from minor premises. In the following example:
\By 3.3;2.2,.6the major premise is Theorem 3.3 and the minor premises are Theorem 2.2 and Note 6. A minus sign is used to indicate that implications are chained. The significance of the punctuation arises simply from the way that rules of inference are stated. For example the modus ponens rule is stored as follows:
$\qvar$ <= $(\pvar \c \qvar)$;$\pvar$The '<=' may be read "follows from." The expression to the left of the '<=' is matched against the goal and the numbered references are fetched and matched against the other logical expressions in the rule.
A match is simply a one-to-one correspondence between the goal and the terms of a reference list, punctuators included, and the corresponding terms of a rule of inference. Thus the meaning of the meaning of the semi-colon, for example, is defined by the stored rules of inference which contain it.
6. The QED
The QED is a justification which is not preceded by a note. The theorem itself is taken as the goal. In form a QED is hardly different from a standard justification except that it begins with '\Bye' instead of '\By'.
Except for short proofs, a proof does not terminate until it reaches a QED. It is a proof syntax error if another theorem is encountered before a QED is reached.
7. Multi-Line Notes
Chains of implications such as the following three lines often occur in proofs where justification is required for each line:
(\pvar \c \qvar)
(\qvar \c \rvar)
(\rvar \c \svar)
but later reference is made only to the overall result that
(\pvar \c \svar).Such a chain can be written using a single note
\note 7 $(\pvar \c \qvar$ \By .2
$\c \rvar$ \By .4
$\c \svar)$ \By .6
Whenever the first symbol on the line of a note is an implies sign, a biconditional, or some transitive relation, then the symbol is taken as indicating a link in a chain of steps of this sort. When reference is made later to the note however, the chain is telescoped, and the intervening links of the chain are omitted. The relations whose transitivity is recognized in this way are those whose transitive properties are stored in the file properties.tex.
8. Line Wrapping
Expressions too long to fit on one line, can be broken into lines and still parsed provided that the expressions on consecutive lines are separated only by white space and an indenting macro.
Indenting Macros
'\linea', '\lineb', '\linec', etc.The first seven of these indenting macros are defined in the file utility.tdf. The macro '\linea' for example is defined as follows:
\def\linea{\vskip 1pt\noindent\hskip 20pt}Altering these definitions in utility.tdf may be done without affecting either the parsing or the checking of math expressions. The remaining nineteen are recognized by the parser and so may be defined as needed by the author. The indenting macros are not to be used in TeX's math mode and hence if a complete math expression is formed by the concatenation ABC, it should occur in the TeX file as:
$A$
\lineb $B$
\lineb $C$
where the indenting macros lie outside the dollar signs.
9. Justification Letters
The following letters can be used in justifications:
'A' a standalone justification for an axiom
'D' a standalone justification for a definition
'G' a standalone justification for a "given" statement. It initiates a block of notes in which the statement is taken as a hypothesis.
'H' for "hence" is used in justifications which terminate a given-hence block
'S' for "set" is used to define locally the value of some variable
10. Given - Hence Blocks
Some notes do not need proof since they are simply hypotheses which are given. Such hypotheses are justified with a "\By G" reference. In subsequent reasoning a note of this sort may be referred to like any other note using its note number. If \qvar has been proven with \pvar as given, a "hence" note, often of the form '(\pvar \c \qvar)', may be stated. For example, suppose that we have as given:
\note 2 $(x \in A)$ \By Gand that by using note 2 we have been able to prove:
\note 7 $(x \in B)$ \By .2,.3,.4We may then use a "hence" rule to infer:
\note 8 $(x \in A \c x \in B)$ \By .7 H .2The notes refered to following the 'H' in a hence rule must be given notes. These given notes are all closed out by the hence rule and may not be referred to subsequently in the proof. Given and hence notes together begin and end blocks of notes. In this example the notes from 2 through 8 form a block. Of these notes only note 8 may be referred to later in the proof.
11. Assignment Statements
Variables may be assigned a value within a proof using a note with a "\By S" justification.
All assignment statements have the form
(<variable> \ident <term >)We may use any term we choose on the right. For example if A is a non-empty set we have that
\note 12 $\Some x (x \in A)$ \By 12.34;.5,.6and it may be useful to set:
\note 13 $(a \ident \an x (x \in A))$ \By SThe following note for example checks:
\note 14 $(a \in A)$ \By .12,.13The "\ident" predicate is Leibniz's identity predicate. It is not exactly the same as ordinary equality. It does not carry any existence presuppositions. Without doing any harm we may for example set 'a' to be an element of the empty-set:
\note 13 $(a \ident \an x (x \in \e))$ \By SWe cannot prove from this that (a \in \e) since for the empty set we have no existence assertion like Note 12. For further details on this logic see the paper.
12. Universalization
Adding a universal quantifier to a statement which has a free variable is called universalization. Such steps are justified by a reference to the statement which is being universalized followed by a 'U'. For example to conclude from the implication:
\note 4 $(k \in M \c k + 1 \in M)$ \By .2,.3that
\note 5 $\Each k (k \in M \c k + 1 \in M)$ \By .4 Uis an example of a valid universalization.
E. Sample Proofs
1. Proof by Contradiction
Proofs by contradiction can be done using given-hence blocks. For example to prove '\Not(x \in A)' we may take as given:
\note 2 $(x \in A)$ \By GIf we are able later to prove the false statement,
\note 7 $ \false$ \By .2,.3,.4we may then use a "hence" rule to infer:
\note 8 $\Not(x \in A)$ \By .7 H .2
2. Proof by Ordinary Induction
Ordinary induction proofs typically involve all of the above proof elements. Theorems to be proven by induction often have the form:
\prop 12.34 $(n \in \nats \c \pbar n)$where '\pbar n' is some expression involving 'n'. In the next few lines we present a roughly hewn template which indicates how to write an ordinary induction proof which can be checked with ProofCheck. This template is based on the ordinary induction theorem (Peano's fifth postulate):
\prop 100.1 $(0 \in M \And \Each n \in M (n + 1 \in M) \c \nats \i M)$Access to this theorem is facilitated by an assignment statement:
An assignment step which is often useful is:
\note 1 $(M \ident \setof n \in \nats \pbar n)$ \By SFollowing this assignment it is useful to apply an unwrapping theorem which turns the assignment statement into a biconditional:
\note 2 $(n \in M \Iff n \in \nats \And \pbar n)$ \By 100.2;.1Using this biconditional a good proof of the usual two steps, the base case and the induction step, the first is usually readily established:
\note 3 $(0 \in M)$ \By .2,...To prove note 3 we must refer to the familiar fact that 0 is a natural number. Although as Peano's first postulate, this familiar fact is found numbered in many places, there is an abundance of very elementary facts of this sort. It is the role of the common notions file to supply notation for these elementary facts. This one has the number 40.1.
The induction step may be done using a given-hence block followed by a universalization. We begin with the usual given:
\note 4 $(k \in M)$ \By GThe bulk of the proof should be inserted here. Again with the help of the biconditional we eventually reach:
\note 5 $(k +1 \in M)$ \By .2,.4We then close the block with a hence statement:
\note 6 $(k \in M \c k +1 \in M)$ \By .5 H .4We then universalize and get
\note 7 $\Each k \in M ( k +1 \in M)$ \By .6 UHaving established both hypotheses of 100.1 we may then draw the conclusion that:
\note 8 $( \nats \i M)$ \By 100.1;.3,.7We then start a chain:
\note 9 $(n \in \nats \c n \in M$ \By .8
$\c \pbar n)$ \By .2We are now ready for a QED:
\Bye .9
F. ProofCheck Work Cycle
Once it is clear what TeX expressions will parse, mathematical text can be written, parsed, and checked using a work cycle analogous to the edit-compile-run work cycle used in writing programs:
Edit the TeX file
Run TeX (or LaTeX)
Run parse
Run check
parse.py and check.py are Python scripts which run on versions of Python from 2.4 up to but not including 3.0.
1. Edit the TeX file
Edit a TeX file as usual to prepare a document.
2. Run TeX (or LaTeX)
Since many of the symbols described above require TeX macro definitions in order to work, files containing these definitions need to be loaded. Most of these simply allow some symbol to be recognized. Many of them are analogous to the macro which defines the symbol \cos for the trig function. A file which contains many of these TeX macro definitions is common.tdf. Hence every TeX document relying on this file needs to include the statement
\input common.tdfIn LaTeX the needed file is common.ldf. Indenting and proof syntax macros are defined in utility.tdf. This file is always needed. For LaTeX the file is utility.ldf Most documents will also need a TeX (or LaTeX) definition file with macros for the constants created in that document. Thus a file geometry.tex will likely need a file geometry.tdf or geometry.ldf.
3. Run parse
Parsing relies on syntactical information stored in a .dfs file. For example a file geometry.tex requires a file geometry.dfs. If this file does not exist parse will create it based on the .dfs files associated with whatever include files are invoked by the .tex file.
When a syntactical error is encountered in the file the program halts and a the line number of the line on which the program halted is printed. Fixing the error requires revising the file of course.
The first time parse runs successfully the file geometry.dfs is extended using the definitions contained in geometry.tex. and a list of proofs contained in the file is stored in geometry.pfs
4. Run check
Getting a proof to check requires running check repeatedly on it until all the steps check. For example to check theorem 2.1 in the file geometry.tex run:
python check.py geometry 2.1There is also one optional argument for the rules of inference file. The default for this is the files rules.tex.
In order to try a particular rule of inference it can be stored in a file, say test.tex, and then called explicitly with
python check.py geometry 2.1 testTo check all the proofs in a file call
python checkall.py geometrywhich relies on the file geometry.pfs to get the numbers of the theorems whose proofs are to be checked.
G. Getting Proofs To Check
There are several reasons that a valid step may fail to check:
1. Several Steps Performed at Once
The author should, if called upon, be able to envision a rule of inference which justifies each step. If two or three valid operations are performed at once, then probably no single rule will justify the step.
2. Elementary Property Assumed
An elementary property may be assumed without explicit reference. At the present stage very few properties are built into ProofCheck. Although the commutative and associative properties of 'and' are built in, the same is not true of 'or' for example. Nor is the symmetry of '=' or 'Iff' built in. Some of this is compensated for by adding extra rules of inference to cover the symmetric cases, but steps can fail to check if they skip over a reference of this sort.
3. Missing Elementary Fact
It may be necessary to add an elementary fact to the common.tex file. These facts should not be added freely. They should only be added if they are basic facts or familiar identities. If an identity provokes the reaction "Of course!" then it is probably legitimate. If it provokes the reaction "Ok, but so what?" then it should probably not be added.
4. Missing Rule of Inference
If a rule can be written down which justifies a step which does not check, the rule can be put into a one line file. If the name of this file begins with "debug", such as "debug123.tex", and is given as the optional third argument to the check.py call:
python check.py <file-name> <theorem-number> debug123then the unifier is called in debugging mode. The output becomes verbose and it should be possible to trace the unification. If this call checks the step then if there is no equivalent rule already in the rules.tex file it can be added. New rules of inference should be equivalent to theorems of logic or the most elementary set theory. Not all valid rules of inference are accepted. For example the rule:
$(pvar And qvar c svar)$ <= $(pvar And qvar And rvar c svar)$;$rvar$will not be recognized by the unifier because of the double match for 'pvar' and 'qvar' inside a conjunction. Too many possible matches would be generated and the rule will simply be passed over. A simpler and slightly more general rule can be used instead:
$(pvar c svar)$ <= $(pvar And rvar c svar)$;$rvar$
5. Weakness in the Unifier
ProofCheck is not intended to be logically complete. There is however a reasonable level of trustworthiness intended. Authors who have a step which they feel should check but which does not should report it.